| 1. 當柴比雪夫定理應用在機率分配上時, 下列敘述何者正確? (A)該定理只適用在對稱的機率分配上 (B)大約 68%的觀測值會落在平均數上下一個標準差之內 (C)至少 25%的觀測值會落在平均數上下兩個標準差之內 (D)至多 11%的觀測值會落在平均數上下三個標準差之外 |
解:$$P(\mu-k\sigma < X < \mu+k\sigma) \ge 1-{1\over k^2}\\(A)\times:不限定任何機率分配\\(B)\times: k=1 \Rightarrow P(\mu-\sigma < X < \mu+\sigma) \ge 1-{1\over 1}=0\\(C)\times: k=2\Rightarrow P(\mu-2\sigma < X < \mu+2\sigma) \ge 1-{1\over 2^2}=0.75\\(D)\bigcirc:k=3 \Rightarrow P(\mu-3\sigma < X < \mu+3\sigma) \ge 1-{1\over 3^2} \Rightarrow P(\mu-3\sigma < X < \mu+3\sigma)\le {1\over 9}=0.11\\故選\bbox[red,2pt]{(D)}$$
| 2. 假設 E 和 F 為兩個非空集合的事件且滿足\(P(F\mid E) = P(F)\), 下列敘述何者錯誤? (A)\(P(E\text{ and }F)=P(E)P(F)\) (B)\(P(E\text{ or }F)=P(E)+P(F)\) (C)E 和 F 為相互獨立事件 (D)\(P(E\mid F)=P(E)\) |
解:$$(A)\bigcirc:P(F\mid E)=P(F) \Rightarrow {P(F\cap E)\over P(E)} =P(F) \Rightarrow P(F\cap E)= P(F)P(E)\\(B)\times: P(E\cup F)=P(E)+ P(F)-P(E\cap F) =P(E)+ P(F)-P(E)P(F)\\(C)\bigcirc: 由(A)知E,F獨立\\ (D)\bigcirc:P(E\mid F)={P(E\cap F)\over P(F)} ={P(E)P(F)\over P(F)} =P(E)\\只有(B)是錯誤的,故選\bbox[red,2pt]{(B)}$$
| 3. 美國密西根州 55%的公民是男性, 45%的公民是女性。 已知本次總統大選該州 60%的男性和 40%的女性投票給共和黨候選人。 請問票投給共和黨候選人的密西根州公民之中, 屬於男性的機率有多少? (A)0.605 (B) 0.736 (C)0.647 (D)0.338 |
解:$${投給共和黨的男性\over 投給共和黨的男性與女性} ={0.55\times 0.6\over 0.55\times 0.6+ 0.45\times 0.4} = {11\over 17} \approx 0.647,故選\bbox[red,2pt]{(C)}$$
| 4. 隨機變數 X 服從指數分配( exponential distribution) , 其機率密度函數為\(f(x)=0.5e^{-0.5x},x>0\)。 請問該指數分配的中位數為多少? (A)2.008 (B)1.649 (C) 1.386 (D) 2.685 |
解:$$中位數為a \Rightarrow \int_0^af(x)\;dx=0.5 \Rightarrow \int_0^a 0.5e^{-0.5x}\;dx=0.5 \Rightarrow \left. \left[ -e^{-0.5x} \right]\right|_0^a=0.5 \\ \Rightarrow 1-e^{-0.5a}=0.5 \Rightarrow e^{-0.5a}=0.5 \Rightarrow -0.5a=\ln 0.5 \Rightarrow a \approx 1.386,故選\bbox[red,2pt]{(C)}$$
| 5. 下列為 108 年公務人員初等考試統計學科目分數的箱型圖( box plot) : |

解:

$$上圖兩個紅箭頭的差距約為40,故選\bbox[red,2pt]{(B)}$$

解:
$$\begin{array}{ccc} 年齡&次數 &累計次數\\\hline 18-23 & 8 & 8 \\ 23-28 & 9 & 17\\ 28-33 & 7 & 24\\ 33-38 & 6 & 30 \\ 38-43 & 6 & 36\\\hline\end{array}\\ 由上表各年齡層的次數可知,此資料並非對稱,而是右偏(數字大的在左半部);\\因此 眾數< 中位數 < 平均數,故選\bbox[red,2pt]{(A)}$$
| 7. 2019 年商學院學生的 TOEIC 成績大約服從一個常態分配, 平均分數\(\mu=610\), 標準差\(\sigma=160\)。某大學 MBA 學程給外國學生的獎學金申請最低門檻是 TOEIC 成績前 3%。 請問 TOEIC 至少要考幾分才能到達此最低門檻? (A)932 (B) 911 (C) 895 (D) 876 |
解:

$$先找z值,滿足P(Z\le z)=1-3\%=0.97,由試題卷的附表(見上圖)可知:z至少為1.88\\因此z={x-\mu\over \sigma}={x-610\over 160}=1.88 \Rightarrow x=160\times 1.88+610 =910.8,故選\bbox[red,2pt]{(B)}$$

解:$$(A)\times: 自由度是n-1\\故選\bbox[red,2pt]{(A)} $$
| 9. 當使用 T 分配來建立母體平均數的信賴區間時, 下列何者假設是不需要的? (A) 樣本平均數的分配必需是常態或近似常態分配 (B) 母體的標準差未知 (C) 樣本數必需很大 (D) 樣本觀測值之間相互獨立 |
解:
$$\bar x\pm t_{\alpha/2}{s\over \sqrt n}的區間估計可以適用於任何大小樣本,故選\bbox[red,2pt]{(C)} $$
| 10. 民調公司想要了解美國公民對現任總統的支持度百分比。 在信心水準 95%和誤差範圍 5%的要求之下, 請問該民調公司至少需要多少樣本數? (A) 297 (B) 385 (C) 897 (D) 1,067 |

| 11. 有關母體參數假設檢定的 P 值( P-value) , 下列敘述何者錯誤? (A)P 值的計算和顯著水準有關 (B)P 值的計算和虛無假設有關 (C)P 值的計算和樣本的檢定統計量有關 (D)P 值越小, 越傾向於拒絕虛無假設 |
![]()
$$ P 值的計算和顯著水準無關,而是P值檢定和顯著水準有關,故選\bbox[red,2pt]{(A)} $$

![]()
$$這題其實不用計算,(B)與(D)的答案是相同的,只要考慮(A)與(C);當然是工廠B的變異較大\\,故選\bbox[red,2pt]{(C)}$$
  |
解:$$ 由成績變異計算t檢定統計量,自由度為8-1=7,故選\bbox[red,2pt]{(D)}$$
| 14. 如果執行卡方適合度檢定( 顯著水準為α ) 時有許多細格( cell) 的期望次數太少, 會造成下列那一種影響? (A)該檢定比較容易拒絕 H0 (B)該檢定的檢定力會變小 (C)該檢定的檢定統計量自由度會變少 (D)不會有任何的影響 |
解:$$次數少容易造成較大的差異,因此容易形成變數間有相關性,也就是容易拒絕H_0,故選\bbox[red,2pt]{(A)} $$
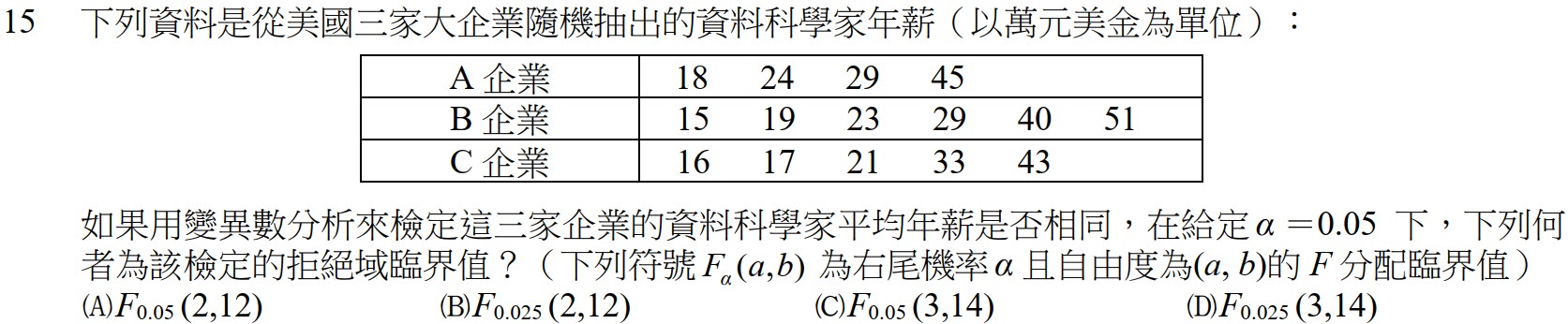 |
解:$$三家企業(k=3),又15位科學家(n=15),因此自由度(a,b)=(3-1,15-1-(3-1))\\=(2,12),故選\bbox[red,2pt]{(A)}$$
 |
 |
解:$$X越大,Y並不隨之變大或變小,X和Y之間幾乎不相關,故選\bbox[red,2pt]{(D)}$$
 |
解:$$R^2=\frac{SSR}{SST}= \frac{300}{900}=0.333 = 33.3\%,故選\bbox[red,2pt]{(A)}$$
 |
解:$$ 圖形接近對稱y=0(上下對稱),因此(A),(B)可能成立;\\又當x越大,y-\hat y變化越大,Y的變異程度並非常數;\\而(D)也可能成立,無法完全判定;故選\bbox[red,2pt]{(C)}$$
. |
解:$$相關係數\rho ={\sum(x-\bar x)(y-\bar y)\over \sqrt{\sum(x-\bar x)^2}\times \sqrt{\sum (y-\bar y)^2}} ={36 \over \sqrt{30}\times \sqrt{48}} ={3\over \sqrt{10}}\\觀察值的測量標準誤=\sqrt{\sum(y-\hat y)^2 \over N-2} =\sqrt{(1-\rho^2)\sum(y-\bar y)^2 \over N-2} = \sqrt{(1-9/10)\times 48 \over 13}\\ = \sqrt{24\over 65}\approx 0.6076 ,故選\bbox[red,2pt]{(D)} $$
| 22. 在複迴歸的模型中加入一個具有高度共線性( collinearity) 的自變數所造成的影響, 下列敘述何者錯誤? (A)最小平方法的估計式可能會不存在 (B)\(R^2\)(判定係數) 可能會變小 (C)某些自變數 X 和 Y 之間的關係可能會被錯誤解釋 (D)某些自變數 X 的係數估計值可能會由正轉成負 |
解:共線性會造成重複的自變數,提高某一自變數的解釋力與預測力,也就是\(R^2\)變大,故選\(\bbox[red,2pt]{(B)}\)。
| 23. 資料中有收入( 低、 中、 高) 及年齡群( 21 歲-30 歲、 31 歲-40 歲、 41 歲-50 歲、 51 歲-60 歲) 兩個變數。 若要以卡方檢定( Chi-square) 檢定收入與年齡群有無關聯性, 其自由度為何? (A) 6 (B) 7 (C) 8 (D) 12 |
解:
$$ 收入分3群、年齡分4群\Rightarrow 自由度=(3-1)(4-1)=6,故選\bbox[red,2pt]{(A)}$$
| 24. 下列那一個假設檢定的程序不適合採用卡方統計量來做檢定? (A)檢定多組獨立的數值資料是否來自相同的機率分配 (B)檢定 Spearman 的等級相關係數( coefficient of rank correlation) 是否顯著 (C)檢定“性別” 和“支持的政黨” 之間是否有關係 (D)檢定迴歸分析的殘差項是否相互獨立 |
解:$$ 順序性不適合採用卡方檢定,故選\bbox[red,2pt]{(B)}$$
| 25. 根據世界綠色和平組織的抽樣調查和迴歸分析, 得到一個估計式\(\hat{Y}=0.5+0.006X\), 其中 Y 為大氣增加的溫度( 華氏℉) , X 為空氣中二氧化碳濃度的增加量( PPM) , 且\(R^2\)高達 0.92。 如果現在將同一筆資料溫度 Y 的單位改成攝氏( ℃) , 並重新計算迴歸估計式, 則下列敘述何者正確? ( 註: 華氏=攝氏\(\times{9\over 5}+32\)) (A)迴歸估計式的截距項變成-31.5 (B)\(R^2\)數值不會改變 (C)X 的係數估計值變成0.0108 (D)迴歸估計式的截距項變成 32.9 |
| 26. 當移動平均數( Moving Average) 的方法用在一時間數列的時候, 下列敘述何者錯誤? (A)此方法可以用來觀察時間數列的長期趨勢( secular trend) (B)此方法可以移除時間數列的不規則變動( irregular variation) (C)當移動期數變大時, 時間數列的波動會變小 (D)此方法可以移除時間數列的季節變動( seasonal variation) |
解:$$移動平均數是跨季節的,與季節無關,故選\bbox[red,2pt]{(D)} $$
 |
解:$$2020年春天\Rightarrow t=10 代入迴歸估計\Rightarrow \hat y=98+6\times 10=158\\,再加上季節因素0.8 \Rightarrow 158\times 0.8= 126.4,故選\bbox[red,2pt]{(A)} $$
| 28. 下列的資料為某班級的考試分數, 分數的四分位距( interquartile range) 為何? 10, 31, 42, 46, 48, 55, 56, 58, 70, 75, 76, 77, 78, 80, 82, 83, 84 (A) 22 (B)32 (C)70 (D)77 |
$$\begin{array}{}序位&1& 2& 3& 4& 5& 6 & 7 & 8 & 9 & 10 & 11& 12 & 13& 14 & 15 & 16 & 17\\\hdashline 分數&10& 31& 42& 46& 48& 55& 56& 58& 70& 75& 76& 77& 78& 80& 82& 83& 84\end{array}\\ \cases{17\times 25\%=4.25 \\ 17\times 75\%=12.75} \Rightarrow \cases{Q_1=第5位數:48\\ Q_3=第13位數:78} \Rightarrow 四分位距=Q_3-Q_1=30,故選\bbox[red,2pt]{(B)} $$
解:
$$ E(9X^2)=9\cdot (-1)^2\cdot f(-1)+ 9\cdot 0^2\cdot f(0)+ 9\cdot 1^2\cdot f(1) =9(f(-1)+f(1))\\ =18f(1)= 18\times {4\over 9} =8,故選\bbox[red,2pt]{(D)}$$
| 30. 假設手稿中的印刷錯誤數量是卜瓦松( Poisson) 分配, 某本 500 頁的手稿有 200 個印刷錯誤。 某頁完全沒有錯誤的機率為何? (A)\(e^{-0.4}\) (B)\(e^{0.4}\) (C)0.4 (D)0.6 |
解:$$ P(X=k)=f(k;\lambda)=\cfrac{\lambda^ke^{-\lambda}}{k!} \Rightarrow f(0,{200\over 500})= e^{-2\over 5}=e^{-0.4},故選\bbox[red,2pt]{(A)}$$
| 31. 一個調查欲研究全國成人玩線上遊戲是否超過四分之三, 用了 400 個成人為全國代表性樣本, 調查發現有 320 個成人玩線上遊戲, 檢定統計量為何? (A)1.1547 (B)2.3094 (C)2.50 (D)3.1254 |
解:$$z=\cfrac{\hat{p}-p}{\sqrt{p(1-p)}/\sqrt n} =\cfrac{320/400-3/4}{\sqrt{(3/4)(1/4)}/\sqrt{400}} ={4\over \sqrt 3} \approx 2.3094,故選\bbox[red,2pt]{(B)} $$
| 32. 某種統計認證的考試分數為常態分配, 平均數為 200 分, 母體標準差為 20 分。 隨機抽取 16 個分數取其平均, 這個平均分數大於 210 分的機率為何? (A)0.9772 (B)0.6915 (C)0.3085 (D)0.0228 |
解:

$$P(Z\gt {210-200\over 20/\sqrt{16}})=P(Z > 2) = 1-P(Z\le 2)=1-0.9772= 0.0228,故選\bbox[red,2pt]{(D)} $$
| 33. 假設母體呈常態分配, 平均數\(\mu\)未知。欲檢定\(H_0:\mu\le 100 \text{ vs. }H_a:\mu > 100\) ,顯著水準設為 0.01。 若將型二錯誤( type II error) 控制為 5%。 當虛無假設\(H_0\)為偽, 拒絕\(H_0\)的機率為何? (A)001 (B)0.05 (C)0.95 (D)0.99 |
解:$$當虛無假設H_0為偽, 拒絕H_0的機率=1-型二錯誤=1-0.05=0.95,故選\bbox[red,2pt]{(C)} $$
| 34. 一個青少年研究, 調查 400 個男生及 400 個女生( 男生及女生為獨立樣本) , 欲探討過去一年中,他們是否曾向父母撒謊。 其中 240 個男生及 200 個女生曾向父母撒謊。 若檢定 \(H_0:\) 男生跟女生曾向父母撒謊的比例沒有差異, 結論為何? (A)若顯著水準(\(\alpha\))為 0.10, 拒絕 \(H_0\); 若顯著水準(\(\alpha\))為 0.05, 則不拒絕\( H_0\) (B)若顯著水準(\(\alpha\))為 0.05, 拒絕 \(H_0\); 若顯著水準(\(\alpha\))為 0.025, 則不拒絕\( H_0\) (C)若顯著水準(\(\alpha\))為 0.025, 拒絕 \(H_0\); 若顯著水準(\(\alpha\))為 0.01, 則不拒絕\( H_0\) (D)若顯著水準(\(\alpha\))為 0.01, 拒絕 \(H_0\); |
解:$$ 已知\cases{男\cases{n_1=400\\ \hat{p_1}=240/400=3/5}\\ 女\cases{n_2=400\\\hat{p_2}=200/400=1/2}} \Rightarrow z=\cfrac{\hat{p_1} -\hat{p_2}}{\sqrt{\cfrac{\hat{p_1}(1-\hat{p_1})}{n_1}+\cfrac{\hat{p_2}(1-\hat{p_2})}{n_2}}} =\cfrac{3/5-1/2}{\cfrac{3/5\cdot 2/5}{400}+ \cfrac{1/2\cdot 1/2}{400}} \\ ={20\over 7} \approx 2.857 > 2.325=z_{0.01} \Rightarrow 拒絕H_0,故選\bbox[red,2pt]{(D)}$$
| 35. 承上題, 如果以卡方檢定( Chi-square) 檢定性別與是否曾向父母撒謊有無關聯性, 其檢定統計量為何? (A)8.08 (B)8.16 (C)400 (D)1,600 |
解:$$ \Rightarrow 觀察值O_i:\quad\begin{array}{c|cc|c} & 男 & 女 &小計\\\hline 說謊 & 240 & 200 &440\\\hdashline 不說謊 & 160 & 200 &360\\\hline 小計& 400 & 400 & 800\end{array} \\ 不分男女,向父母撒謊比率p={240+200 \over 400+400}={11\over 20}\\期望值E_i:\quad \begin{array}{c|cc|c} & 男 & 女 &小計\\\hline 說謊 & 400\times p=220 & 400\times p=220 &440\\\hdashline 不說謊 & 400-220=180 & 400-220=180 &360\\\hline 小計& 400 & 400 & 800\end{array} \\ \Rightarrow \chi^2 = \sum {(O_i-E_i)^2 \over E_i} ={(240-220)^2\over 220} +{(200-220)^2\over 220} +{(160-180)^2\over 180} +{(200-180)^2\over 180} \\ ={800\over 220} +{800\over 180} \approx 8.08,故選\bbox[red,2pt]{(A)} $$
| 36. 一般科幻小說平均 290 頁。 某出版社隨機選擇他們出版的 16 部小說, 其平均長度為 335 頁, 標準差為 48 頁。 欲檢定這出版社的小說是否明顯比一般科幻小說長, 根據以上資料, 得出結論為: (A)若顯著水準(\(\alpha\))為 0.10, 拒絕 \(H_0\); 若顯著水準(\(\alpha\))為 0.05, 則不拒絕\( H_0\) (B)若顯著水準(\(\alpha\))為 0.05, 拒絕 \(H_0\); 若顯著水準(\(\alpha\))為 0.025, 則不拒絕\( H_0\) (C)若顯著水準(\(\alpha\))為 0.025, 拒絕 \(H_0\); 若顯著水準(\(\alpha\))為 0.01, 則不拒絕\( H_0\) (D)若顯著水準(\(\alpha\))為 0.01, 拒絕 \(H_0\); |
解:

$$H_0:出版社的小說比一般科幻小說長\\檢定統計量t_{df=16-1}={335-290 \over 48/ \sqrt{16}} \Rightarrow t_{15}={15\over 4}=3.75\\查表知:3.75 > 3.733 (t_{df=15,\alpha=0.001}) \Rightarrow 拒絕H_0;\\也就是說無論\alpha=0.1,0.05,0.025,還是0.01,結果都是拒絕H_0,故選\bbox[red,2pt]{(D)} $$
 |
解:$$由該表可知 \hat y=2.8x-1.2,將x=6代入可得\hat y=2.8\times 6-1.2=15.6\\,因此殘差為y-\hat y=14-15.6=-1.6,故選\bbox[red,2pt]{(B)} $$註:本題的表格應該是EXCEL產生,其中標準誤所代表的涵意,請參考EXCEL的說明。
| 38. 一個資料中只有收入( 低、 中、 高) 及年齡群( 21 歲-30 歲、 31 歲-40 歲、 41 歲-50 歲、 51 歲-60 歲)兩個變數。 若要將收入、 年齡群及兩個變數的交互作用以虛擬變數放入迴歸模型當自變數, 會有幾個自變數? (A) 7 (B) 9 (C) 11 (D) 12 |
解:$$3\times 4-1=11,故選\bbox[red,2pt]{(C)} $$
 |
解:
$$由題意知\cases{北區(x_i):\bar x=33, s_x^2=24,n_x=5\\ 中區(y_i):\bar y=29, s_y^2=17.5,n_y=5\\ 南區(z_i):\bar z=28, s_z^2 =9.5, n_z=5\\} \Rightarrow 總平均\bar{\bar x} ={n_x\bar x+ n_y\bar y+ n_z\bar z\over n_x+n_y+ n_z} \\={5(33 +29+28)\over 15}=30 \\ \Rightarrow SS_B= n_x(\bar x-\bar{\bar x})^2 +n_y(\bar y-\bar{\bar x})^2 +n_z(\bar z-\bar{\bar x})^2 =5((33-30)^2 + (29-30)^2 +(28-30)^2)\\ =5(9+1+4) = 5\times 14=70,故選\bbox[red,2pt]{(D)} $$
| 40. 假設過去的資料顯示 60%的大學生喜歡 C 牌的可樂, 隨機抽取 5 名學生至少有 1 名學生喜歡 C 牌可樂的機率為何? (A)0.07776 (B)0.2 (C)0.92224 (D)0.98976 |
解:$$P(至少1名喜歡)=1-P(全部不喜歡)=1-(0.4)^5=0.98976,故選\bbox[red,2pt]{(D)} $$

解題僅供參考
沒有留言:
張貼留言